BKB3WV4 – Bouwkunde als wetenschap
-
Intro
-
Line 1: Clustering and Classification for Data Analysis
-
Line 2: Parametric Optimisation for Data Generation
Information
| Course Code | BKB3WV4 |
| Last updated | November 8, 2025 |
| Keywords | |
| Primary study | Bachelor |
| Secondary study | BK Bachelor |
Responsible
| Teachers | |
| Faculty |
BKB3WV4 – Bouwkunde als wetenschap 0/2
BKB3WV4 – Bouwkunde als wetenschap
During WV4 you learn how to analyse datasets and generate data for research purposes.
The WV4 course is organized in three modules. The computational methods module, the philosophy of science module, the writing module. The three modules are interrelated and converge into one final deliverable (paper), which will be assessed at the end of the course.
The computational methods module includes one introductory lecture; and four workshops that include self-study preparation, mandatory in class attendance, and one deliverable per each workshop. The computational methods module serves to write one specific section of the final paper.
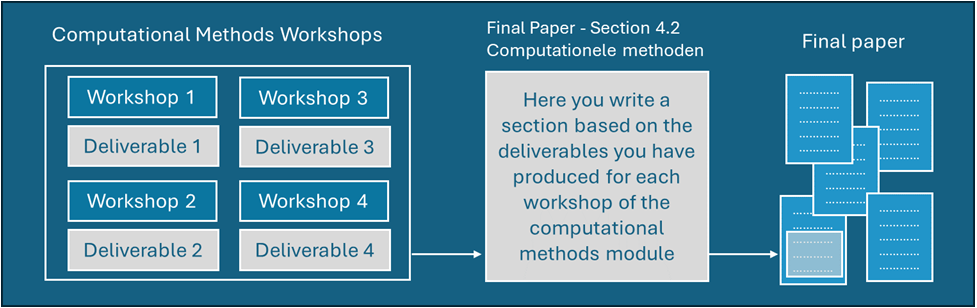
During the first 3 weeks of the WV4 course, you will follow 4 computational workshops about computational research methods. The workshops use blended learning methods. Before you attend each workshop in class, you must prepare with self-study. The activities in class build upon what you prepared in the self-study. After each workshop, you need to submit a deliverable. All the course information and the deliverables can be found on Brightspace page of BKB3WV4.
The Computational methods module of the WV4 course offers several workshop lines. As a student, you will be assigned to one of the two lines at the beginning of the course.
BKB3WV4 – Bouwkunde als wetenschap 1/2
Line 1: Clustering and Classification for Data Analysislink copied
In this workshop line, you familiarise with how to select and organize an existing dataset, and how to analyse it by using machine learning methods for clustering and classification. You will familiarise with what can be done with each of the two methods, and for what each of the two methods can be used. You will look at examples that used machine learning methods for clustering and classification to extract information from datasets in research.
Workshop 1: Datasets for Research ML Applications
The workshop ‘Datasets for Research ML Applications’covers finding and adjusting a dataset for research purposes while considering data ethics and accuracy.
The self-study for this workshop consists of studying the workshop terminology about finding datasets, different data types and using data analysis methods and machine learning methods for research purposes. The second part of the self study consists of follwoing the exercise, in which you will get familiar with using Python coding.
Workshop 2: Pre-processing data for ML purposes
This workshop covers pre-processing an existing dataset to make it suitable for machine learning applications. Specifically, the workshop will explain how to:
- Analyse a dataset to extract information about the data distribution and identify outliers.
- Perform data cleaning and normalisation.
- Use feature engineering to remove irrelevant data from the dataset and improve the performance of machine learning models.
The self-study for this workshop consists of studying the workshop terminology about outliers and normalisation. The second part of the self study consists of follwoing the exercise, in which you will pre-process an example dataset.
Workshop 3: Dataset analysis with Classification
This workshop introduces supervised machine learning methods for classification, which require a dataset labelled with binary or categorical classes. These methods can be used to (1) build a classifier, i.e. a model that learns from the dataset to predict the correct class for any new input data point, and (2) identify the key features that affect the classification accuracy.
The self-study for this workshop consists of studying the workshop terminology about classification. The second part of the self study consists of follwoing the exercise, in which you will apply classification to a simplified example and the example dataset. Additionally, there is an extra exercise which showcases classification with a real-world dataset.
Workshop 4: Dataset analysis with Clustering
This workshop introduces unsupervised learning methods to extract patterns from unlabelled datasets. It demonstrates using clustering algorithms to capture similarities between data points and group them accordingly. Clustering can be used to answer exploratory research questions like: can we identify different types of households based on housing preferences and living conditions?
The self-study for this workshop consists of studying the workshop terminology about classification. The second part of the self study consists of follwoing the exercise in which you will apply classification to a simplified example and the example dataset.
BKB3WV4 – Bouwkunde als wetenschap 2/2
Line 2: Parametric Optimisation for Data Generationlink copied
In this workshop line, you familiarise with parametric modelling, computational simulations, and multi-objective optimisation to support research. You will look at examples that used parametric modelling with various parameterisation strategies, various types of computational simulations, and various formulations of optimisation problems to investigate research subjects in the built environment.
Workshop 1: Parametric Modelling
In the first section, you learn about some difference between using parametric modelling, simulations, and optimisation to support design decisions and to generate data to support research investigations. In the second section, you learn about selecting parameters, variables and constraints for form generation for research.
The self-study for this workshop consists of studying the workshop terminology about data generation workflows and selecting parameters, variables, and constraints. The second part of the self study consists of follwoing the exercise in which you will select parameters, variables and constraints for an example.
Workshop 2: Simulations
This workshop explains how simulations can be set to use for research purposes. The workshop focuses on simulation accuracy. The first section of this workshop explains the importance of selecting the correct level of detail for the research project. The second section of the of this workshop explains verification, validation and calibration are used to improve the accuracy of simulations. Additionally, there is an explanation on performance gaps and how real-world measurements can be used to calibrate a simulation.
The self-study for this workshop consists of studying the workshop terminology about level of detail, verification and performance gaps. The second part of the self study consists of follwoing the exercise in which you see the impact of the level of detail on the accuracy of a simulation.
Workshop 3: Optimization
This workshop explains how to select variables and objectives for the optimization for research and explains the different optimization methods. The first section of this workshop explains how to select variables and objectives in a sensible way. The second section of this workshop explains different optimization methods.
The self-study for this workshop consists of studying the workshop terminology about objectives and optimization methods. The second part of the self study consists of follwoing the exercise in which you set-up and run an optimization model for research data generation.
Workshop 4: Data Analysis
The workshop ‘Data analysis’ explains to analysis methods on how the generated data from simulation and optimization methods can be interpret for research purposes. The first section explains how the parallel coordination plot can be used to draw conclusions from simulation data. The second section of the workshop explains how to select results from optimization data and how to use the pareto front.
The self-study for this workshop consists of studying the workshop terminology about the parallel coordinate plot and the pareto front. The second part of the self study consists of follwoing the exercise in which you analyse the results of a multi-objective optimization for research purposes.
Write your feedback.
Write your feedback on "BKB3WV4 – Bouwkunde als wetenschap"".
If you're providing a specific feedback to a part of the chapter, mention which part (text, image, or video) that you have specific feedback for."Thank your for your feedback.
Your feedback has been submitted successfully and is now awaiting review. We appreciate your input and will ensure it aligns with our guidelines before it’s published.