WV4 Line 1 – Workshop 1 – Datasets for Research and ML Applications
-
Intro
-
Selecting a dataset and data types:
-
Machine learning for research
Information
| Primary software used | Python |
| Software version | 1.0 |
| Course | WV4 Line 1 – Workshop 1 – Datasets for Research and ML Applications |
| Primary subject | AI & ML |
| Secondary subject | Machine Learning |
| Level | Intermediate |
| Last updated | March 4, 2025 |
| Keywords |
Responsible
| Teachers | |
| Faculty |
WV4 Line 1 – Workshop 1 – Datasets for Research and ML Applications 0/2
WV4 Line 1 – Workshop 1 – Datasets for Research and ML Applications
Explanation of basic concepts on using datasets and machine learning for research purposes.
This workshop provides you with the basic concepts and terminology you use in Workshop 1 Datasets for research and machine learning applications. This workshop covers finding and adjusting a dataset for research purposes while considering data ethics and accuracy. Additionally, it gives an explanation on different data types and how to use Machine Learning for research purposes.
WV4 Line 1 – Workshop 1 – Datasets for Research and ML Applications 1/2
Selecting a dataset and data types:link copied
Data research types
Research involves collecting and analysing data. The researcher can either collect data themselves or use third-party datasets. In the first case, we talk about ‘primary research’, whereas in the second, we have ‘secondary research’. Both research approaches have pros and cons.
- Primary research gives you control over data selection and formatting, but collecting data from scratch is time-consuming.
- Secondary research takes advantage of large existing datasets, yet it is not always possible to determine how data were generated. The researcher must check data quality and consistency before using the dataset, and pre-process the data to make it suitable for their intended application.
Finding a dataset
There are existing datasets you can use for your project. Some of these are freely available on web repositories such as 4TU.ResearchData and Kaggle. Once you find a dataset, you must check whether it meets all the requirements for your project. If it doesn’t, you might have to perform additional actions, such as:
- collecting additional data
- Identify features relevant to the problem you are trying to solve
- preprocess the dataset by identifying and removing outliers, normalising data or changing the data format.
Before selecting a dataset, you should always check (1) how the data were collected, and (2) if the data were gathered ethically. Both aspects affect the quality and reliability of the dataset.
Ethical considerations
Ethical considerations apply to both data retrieval and storage. A dataset should be constructed following the principle of data transparency, meaning that collection methods, purpose and data sources are fully disclosed. Lack of transparency can undermine the societal acceptance of the research outcomes.
Ethical concerns involve privacy and data protection. For example, data on building occupants may include personal information (e.g., location, habits, health). To protect the occupants’ privacy, datasets must be anonymised. Similarly, when using data collected from interviews, one must ensure that participation in the interviews is voluntary and that data are anonymous.
Another ethical issue is bias, because datasets may underrepresent certain groups or environments, leading to biased conclusions.
Data quality
When using an existing dataset, it is essential to check the quality of the collected data. The data should be up-to-date and complete. Outdated or missing data can lead to incorrect conclusions and affect the validity of the research.
Producing or collecting data is a time-consuming process. This is the main reason for selecting an existing dataset over building your own. However, since you don’t have control over how these data were collected, you should check if the measurements or simulation methods used by the dataset creator are reliable.
Data Types
Data type refers to the kind of value a data point can have. Data can be classified as either quantitative (numerical) or qualitative. Quantitative data is anything that can be measured on a scale. Qualitative data, such as thoughts or feelings, cannot be measured on a scale.
Qualitative data can be:
- Nominal data is represented by labels that are not ordered or measurable. Examples are ‘gender’ or ‘city of residence’.
- Ordinal data, represented by labels that are ordered but not measurable. Examples include rankings such as ‘good’, ‘average’ and ‘poor’.
Quantitative data comes in two forms:
- discrete data, consisting of whole numbers like the number of cars a person owns.
- continuous data, consisting of a value within a range like the height of an individual or time.
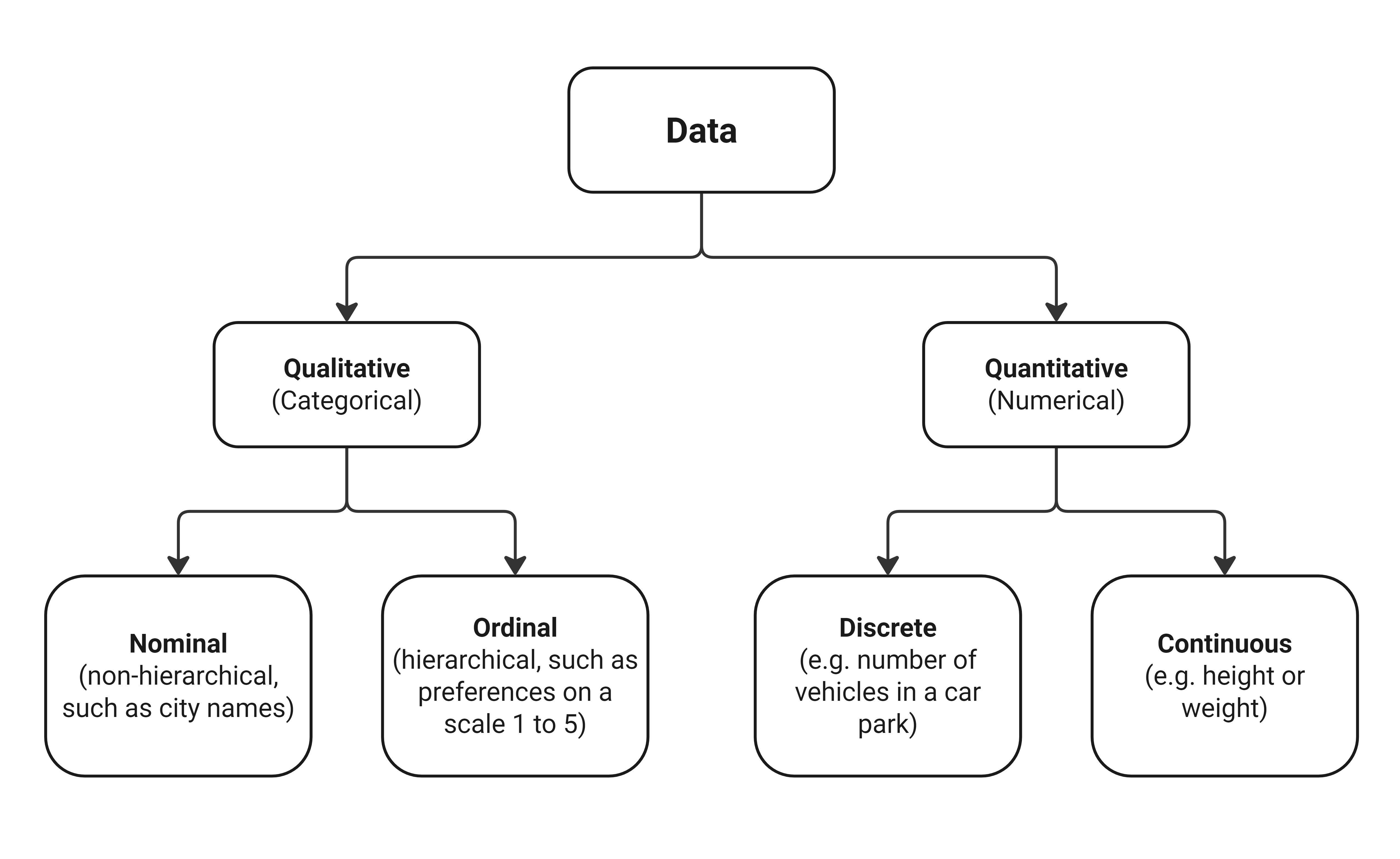
Qualitative data must be encoded as numbers before it can be used for quantitative research. For example, if you have three cities, Delft, Rotterdam, and Amsterdam, they can be encoded as 0, 1, and 2, respectively.
There are different kinds of encoding, such as ‘one-hot encoding’, ‘label encoding’, and ‘ordinal encoding’. If your dataset includes qualitative data, review different encoding methods and select the most appropriate for your application.
If you want to learn more about different types of research methods, or data types you can go to:
Debate A: Selecting a dataset
If you are following this tutorial because you are attending the course BK3WV4, after you have learned the theory and practised the exercises, you will attend a workshop in class at TU Delft. The workshop lasts 3 hours. During the workshop, you will work with the tutors. Two hours are contact hours with your tutor and one hour is for activities without tutors. During the first one hour, you will discuss the tutorial with the tutor and your classmates. During the second hour, you will write a first draft of your workshop deliverable. During the third and fourth hour, you will discuss how the content of the workshop relates to your research question.
- What type of data is needed for your research? Would your research benefit more from qualitative or quantitative data, or both?
- How would you check the data quality and ethicality of a dataset?
WV4 Line 1 – Workshop 1 – Datasets for Research and ML Applications 2/2
Machine learning for researchlink copied
Using Data Analysis and Machine Learning methods for research
Quantitative research uses Data Analysis methods, such as descriptive statistics, correlation analysis, and hypothesis testing, to find correlations, patterns or trends in numerical data. However, when dealing with large and complex datasets traditional analysis methods can become computationally inefficient. In these cases, Machine Learning can help by automating pattern recognition and making the analysis more scalable. Machine learning methods can also be used to make predictions, understand the relationship between data points, cluster and classify data.
Machine learning classifications
Machine learning models can be broadly classified as supervised and unsupervised learning.
- Supervised learning requires a labelled dataset, where the input data is paired with corresponding outputs. The goal is to learn a function that maps inputs to the correct outputs.
- Unsupervised learning works with unlabelled data and focuses on discovering underlying patterns or groupings within the dataset.
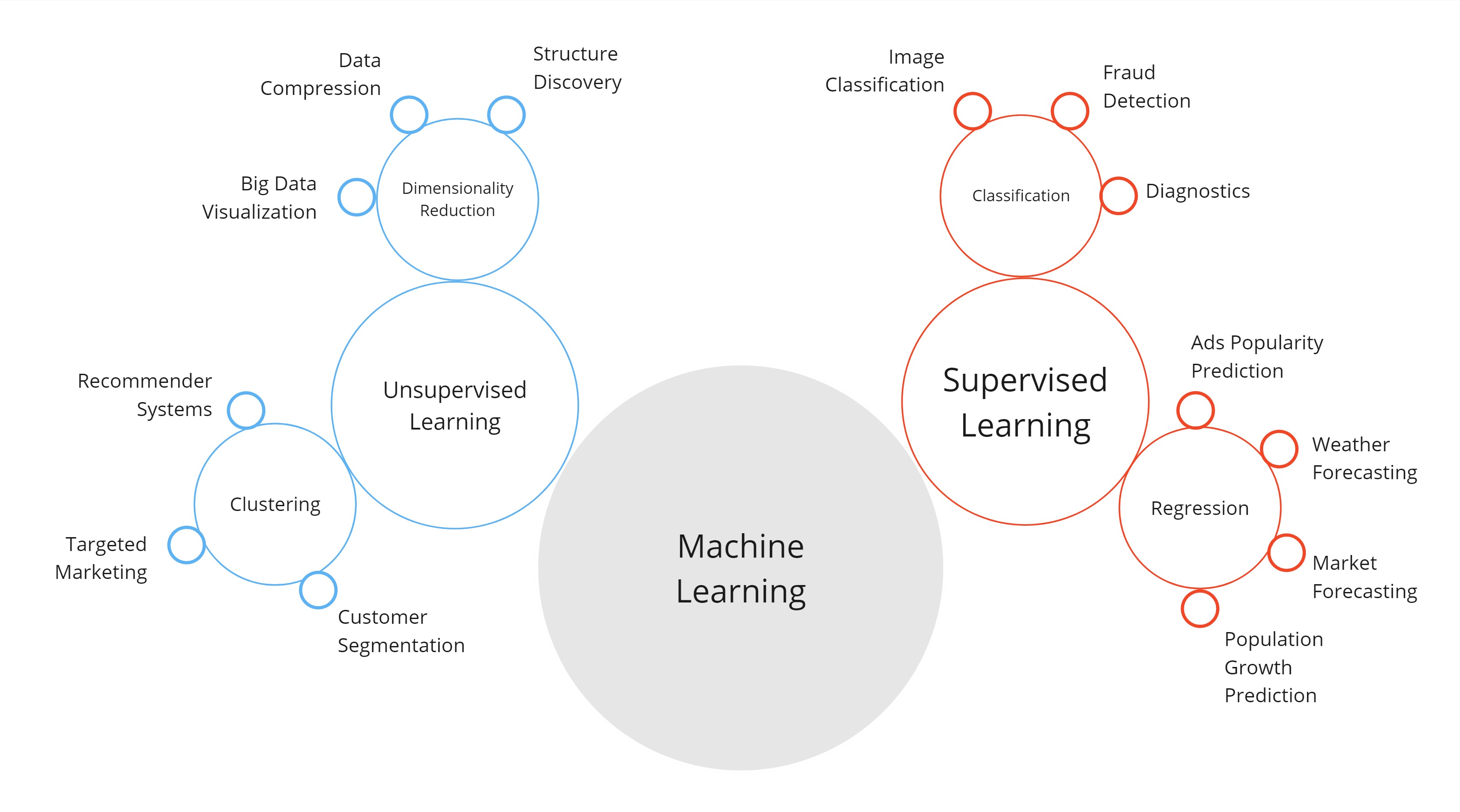
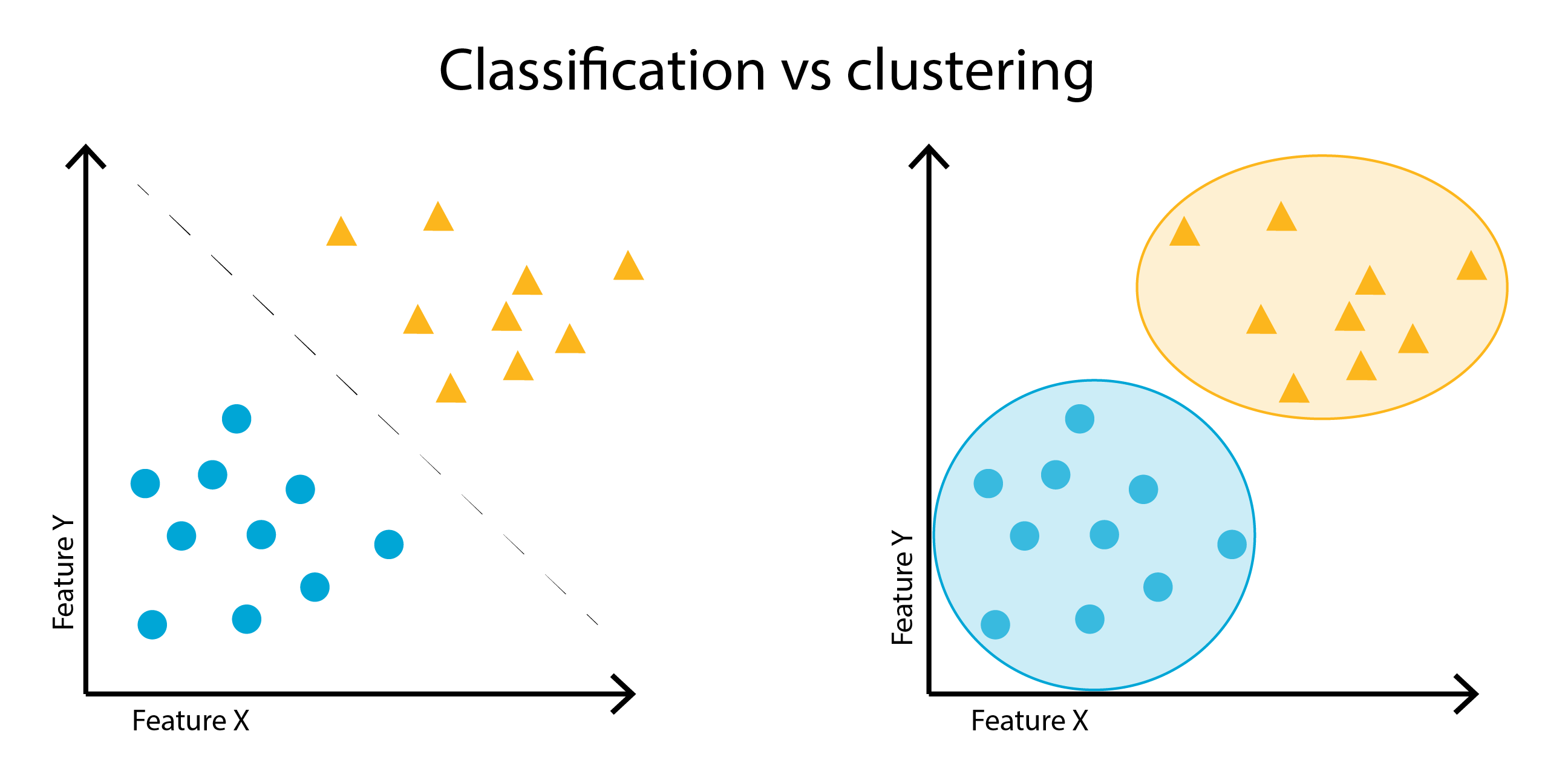
In this workshop line, you will explore a supervised learning method for classification and an unsupervised learning method for clustering.
- Classification is the task of predicting a discrete target variable (e.g., categorising emails as ‘spam’ or ‘not spam’).
- Clustering involves grouping data based on their similarity (e.g., grouping animals based on their characteristics)
Exercise: Getting started with Python in Google Colab
For this workshop the exercise is used as a preparation for the coming workshops. During the BKB3WV4 computational line 1 you will use python inside Google Colab for all the exercises. Because of that it is at essence that you will get a basic understanding of Python. During this exercise we will walk you through your first steps of using Python, and the exercise explains all the essentials you will need during the coming workshops of the course. In addition to basic Python scripting two libraries are explained: Pandas and Matplotlib, which will be extensively used during the next exercises. If you already have basic understanding of Python, it is still good to follow the exercise as a refresher, and to check if you have all the knowledge you need for this course. Additionally, you will get familiar with the dataset that will be used for all the next exercises.
Debate B: ML for research
If you are following this tutorial because you are attending the course BK3WV4, after you have learned the theory and practiced the exercises, you will attend a workshop in class at TU Delft. The workshop lasts 3 hours. During the workshop, you will work with the tutors. Two hours are contact hours with your tutor and one hour is for activities without tutors. During the first one hour, you will discuss the tutorial with the tutor and your classmates. During the second hour, you will write a first draft of your workshop deliverable. During the third and fourth hour, you will discuss how the content of the workshop relates to your research question.
- Create a first idea of how you could use data analysis methods for your research direction?
- Create a first idea of how you could use machine learning for your research direction?
Write your feedback.
Write your feedback on "WV4 Line 1 – Workshop 1 – Datasets for Research and ML Applications"".
If you're providing a specific feedback to a part of the chapter, mention which part (text, image, or video) that you have specific feedback for."Thank your for your feedback.
Your feedback has been submitted successfully and is now awaiting review. We appreciate your input and will ensure it aligns with our guidelines before it’s published.