WV4 Line 1 – Workshop 2 – Pre-processing data for ML purposes
-
Intro
-
Feature Selection Through Literature
-
Outliers, normalisation and data cleaning:
Information
| Primary software used | Python |
| Software version | 1.0 |
| Course | WV4 Line 1 – Workshop 2 – Pre-processing data for ML purposes |
| Primary subject | AI & ML |
| Secondary subject | Machine Learning |
| Level | Intermediate |
| Last updated | November 27, 2024 |
| Keywords |
Responsible
| Teachers | |
| Faculty |
WV4 Line 1 – Workshop 2 – Pre-processing data for ML purposes 0/2
WV4 Line 1 – Workshop 2 – Pre-processing data for ML purposes
This page gives information on preprocessing data for machine learning purposes.
This workshop covers pre-processing an existing dataset to make it suitable for machine learning applications. The first section of the workshop explains how to use feature engineering to remove irrelevant data from the dataset and improve the performance of machine learning models. The second section of the workshop will explain how to analyse a dataset to extract information about the data distribution and how to identify outliers. The workshop also explains how to perform data cleaning and normalisation for pre-processing datasets.
WV4 Line 1 – Workshop 2 – Pre-processing data for ML purposes 1/2
Feature Selection Through Literaturelink copied
What is a feature?
In machine learning, a feature is an individual measurable property or characteristic of the data that is used as an input to the model. Features can represent different aspects of the data. For example, in a dataset about houses, features can include the size of the house, the number of bedrooms, and the location. These variables, whether qualitative or quantitative aspects of a home, will be represented by numbers.
It is important to note that not all features in a dataset may be relevant or useful for a specific research application. Some features may have little or no influence on the outcome you’re trying to predict, or they might introduce noise, making it harder for the model to learn patterns effectively. To overcome these issues, researchers use feature engineering.
Data noise
Data noise is any disturbance that alters the information content. In an audio signal, for instance, noise can be caused by high loudness across indistinct frequencies, undermining the clarity of the sound.
Systematic errors in data recording or storage can generate noise. For instance, recording the internal temperature of different houses in a neighbourhood using instruments that are not necessarily calibrated can introduce measurement inconsistencies.
In general, if data noise characterises the entire dataset and has low intensity, a machine learning model may still filter it out during the learning process. If, however, the noise is inconsistent and significantly affects the feature values, it should be addressed through data preprocessing techniques.
Feature engineering
Feature engineering is the process of selecting or modifying features of an existing dataset or creating new ones (for instance, by combining two existing features into one) to improve the performance of a machine-learning model. It involves:
- removing irrelevant features
- transforming data (e.g., scaling or normalizing)
- creating new features
Feature selection
Your research question should always guide feature selection. For example, if your research question is: “What factors influence house prices?” relevant features might include size, number of rooms, location, etc. Less relevant features, like the house colour, are unlikely to contribute meaningfully to this question.
A good strategy to select features pertinent to your research question is to look for examples in the literature. By reviewing previous studies, you can learn about how datasets have been prepared to address similar research problems, what features were selected, and the impact of these features on the predictive capabilities of the machine learning model.
If you want to learn more about how to select impactful features from a dataset, you can follow the tutorial at the link below. Note that this is an advanced tutorial, and you will need an adequate level of Python coding and understanding of machine learning principles to follow it.
Example papers
The following papers give a clear explanation on how the discussed terminology can be used during research. We highly recommend you look at these papers.
“Building feature-based machine learning regression to quantify urban material stocks: A Hong Kong study” by Yuan et. al. (2023)
- https://doi.org/10.1111/jiec.13348
- Selecting features
- Framework of proposed quantification approach
- Data collection and data preparation
Debate A: Selecting features
If you are following this tutorial because you are attending the course BK3WV4, after you have learned the theory and practiced the exercises, you will attend a workshop in class at TU Delft. The workshop lasts 3 hours. During the workshop, you will work with the tutors. Two hours are contact hours with your tutor and one hour is for activities without tutors. During the first one hour, you will discuss the tutorial with the tutor and your classmates. During the second hour, you will write a first draft of your workshop deliverable. During the third and fourth hour, you will discuss how the content of the workshop relates to your research question.
- How do you decide which features are essential for your research, and which can be excluded?
- How could improperly selected features affect the performance of your ML model?
WV4 Line 1 – Workshop 2 – Pre-processing data for ML purposes 2/2
Outliers, normalisation and data cleaning:link copied
The first step for any research project, especially those relying on machine learning models, is determining whether the dataset is consistent. Machine learning models expect data to be well-structured and clean. The model’s prediction might be wrong or inaccurate if the data is inconsistent (e.g., missing values or features on different scales). To guarantee data consistency, one must first analyse the dataset distribution.
Dataset distribution
Dataset distribution refers to how data points are spread across different values or ranges for each feature. Understanding the distribution helps to:
- Detect skewness (e.g., one feature has more values clustered at one end of the scale, while others are spread out evenly).
- Identify imbalance in target labels (important for classification problems, where having significantly more instances of one class over another could lead to biased predictions).
- Identify outliers
Outliers
Outliers are data points that significantly deviate from the rest of the dataset. They might represent rare events, errors in data collection, or unusual variations. For example, in a dataset of house prices, an outlier could be a house priced much higher or lower than others.
Outliers can generate significant issues in machine learning applications. For instance, a few extreme values could shift a regression curve towards points not representative of the dataset. For this reason, you should identify and remove any potential outliers in your dataset.
Outliers can be identified visually through scatter plots or boxplots, or by measuring the distance of each data point from the mean of the dataset using methods like Z-scores.
Detecting Outliers Using Z-Score
One technique that can be implemented to detect outliers are the z-score values. The z-score value calculates how far a given data point from the mean of a group expressed in standard deviations. It tells us how far a given data point is from the group mean of 1 feature, allowing us to identify values that fall significantly outside the typical range.
Calculating the z-score requires us to know the mean and the standard deviation of the feature.
Where:
- Z is the z-scoreù
- X is the observed value
- μ is the mean of the sample
- σ is the standard deviation of the sample
Data normalisation
Data normalisation ensures that all features have the same scale, preventing certain features from dominating the learning process due to differences in their magnitudes. There are two main approaches to Data Normalization:
- Min-Max Normalization: scales the values of each feature to a range between 0 and 1. Best selected when you want all features to be within a fixed range, commonly used when you know that your data doesn’t contain extreme outliers.
- Z-Score Normalization (Standardization): scales the values of each feature to have a mean of 0 and a standard deviation of 1. Useful when your data follows a normal distribution, as it centres the data around 0 and makes it easier to compare features with different units
To learn more about data cleaning in the Data cleaning guide by Scribbr
Min-max normalisation
The min-max normalization is expressed as follows:
Where:
- X is the original value
- X^’ is the normalized value
- Xmin is the minimum value
- Xmax is the maximum value
The outcome of this operation will turn the feature from whatever minimum and maximum value into a new range from 0 to 1 float values.
Pre-processing other data types
The data pre-processing techniques, including analysis of the dataset distribution, data cleaning and normalisation described above apply to all sorts of data, not just numerical ones. In fact, data is anything that numbers can represent. This includes images, where data is the information contained in each pixel (1 value per pixel location in a greyscale image or 3 values per pixel location in an RGB image), or audio samples, where data can store information about a sound loudness per frequency band over a specific time interval.
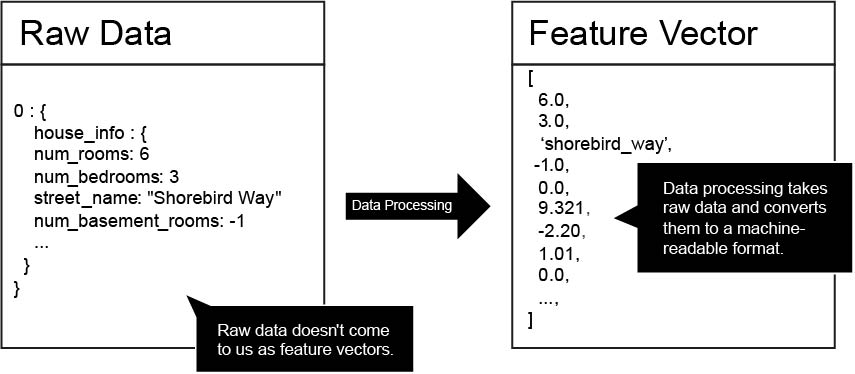
So far, we have seen examples in which raw data is converted as a feature vector before being passed to a machine learning model (Figure 3). This is because standard machine learning models can’t extract features from complex data structures like images, on their own. In technical terms, standard machine learning models can’t learn ‘representations’ from data.
More advanced machine learning models, such as Artificial Neural Networks (ANNs) (the backbone of modern Artificial Intelligence applications), instead have an intrinsic ability to learn representations from many different data formats. These methods can also be used to perform advanced tasks, including generating text and images (see for instance the popular software Chatgpt and Midjourney).
Exercise: Pre-processing a dataset
To get a better understanding on how to pre-process a dataset for research purposes you should follow this example with the WoON21 dataset. In the exercise you will work with the WoOn21 dataset and learn how to recognize outliers, select features and normalise the data.
Example Papers
The following papers provide a clear explanation of how the discussed terminology can be used during research. We highly recommend you to look at these papers.
- “Energy characteristics of urban buildings: Assessment by machine learning” by Tian et al. 2021
- https://doi.org/10.1007/s12273-020-0608-3
- Explorer the energy characteristics of London using ten machine learning algorithms from three aspects
- Tuning process of a machine learning model
- Variable importance
- Spatial analysis of model discrepancy
- Ranking and impact of variables
Debate B: Pre-processing a dataset
If you are following this tutorial because you are attending the course BK3WV4, after you have learned the theory and practiced the exercises, you will attend a workshop in class at TU Delft. The workshop lasts 3 hours. During the workshop, you will work with the tutors. Two hours are contact hours with your tutor and one hour is for activities without tutors. During the first one hour, you will discuss the tutorial with the tutor and your classmates. During the second hour, you will write a first draft of your workshop deliverable. During the third and fourth hour, you will discuss how the content of the workshop relates to your research question.
- Would you expect outliers in your ideal numerical dataset, if so where?
- What would an outlier look like if your dataset consisted of images or audio?
- What steps would you follow to clean an existing dataset for your research?
- How would you normalise the data, if your dataset consisted of images or audio?
Write your feedback.
Write your feedback on "WV4 Line 1 – Workshop 2 – Pre-processing data for ML purposes"".
If you're providing a specific feedback to a part of the chapter, mention which part (text, image, or video) that you have specific feedback for."Thank your for your feedback.
Your feedback has been submitted successfully and is now awaiting review. We appreciate your input and will ensure it aligns with our guidelines before it’s published.