Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations
-
Intro
-
Environment Setup
-
Description of program structure and design choices
-
Main difficulties and solutions
-
Limitations of the Design
Information
| Primary software used | Python |
| Software version | 1.0 |
| Course | Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations |
| Primary subject | AI & ML |
| Secondary subject | Machine Learning |
| Level | Beginner |
| Last updated | June 23, 2025 |
| Keywords |
Responsible
| Teachers | |
| Faculty |
Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations 0/4
Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations
This file serves as a documentation for the project Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations. The project is part of the Capstone course for the Engineering with AI minor at the TU Delft.
This page will describe how to reproduce the results in our presentation. To run the more demanding parts in a reasonable time, GPU inference is recommended which requires special setup and hardware.
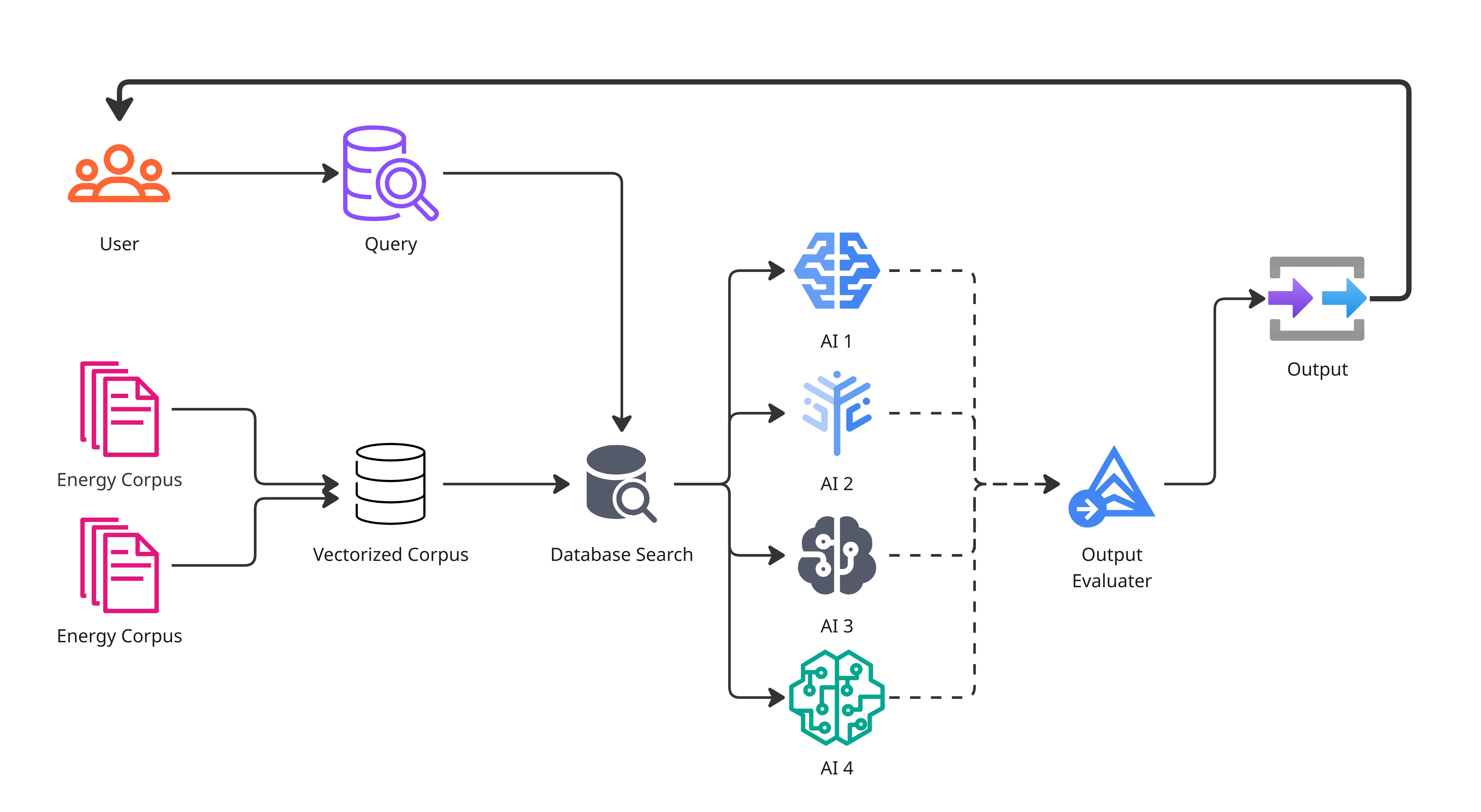
Project Information
- Title: Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations
- Author(s): Stefan Bojilov, Mate Cser, Kees de Hoogh
- Supervisor: Tong Wang, Luciano Siebert, Koray Bingol and Amir Homayounirad
- Year: 2024
- Type: Capstone Applied AI project 2024-2025 Q2
Citation Guide
BibTeX
@misc{bojilov2024leveraging,
title = {Leveraging Large Language Models for Policy Document Retrieval Information in Energy Renovations},
author = {Bojilov, Stefan and Cser, Mate and de Hoogh, Kees},
year = {2024},
howpublished = {Capstone Applied AI project, TU Delft},
note = {Last updated June 23, 2025},
url = {https://digipedia.tudelft.nl/tutorial/leveraging-large-language-models-for-policy-document-retrieval-information-in-energy-renovations/?tab=chapter-0}
}APA: Bojilov, S., Cser, M., & de Hoogh, K. (2024). Leveraging large language models for policy document retrieval information in energy renovations [Capstone Applied AI project]. TU Delft. https://digipedia.tudelft.nl/tutorial/leveraging-large-language-models-for-policy-document-retrieval-information-in-energy-renovations/?tab=chapter-0
Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations 1/4
Environment Setuplink copied
Setting up the environment
Clone this repository (or extract the zip file). Open a terminal in the root folder: Capstone-RAG-project.
Make sure to use python 3.12. Run pip install -r requirements.txt --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cpu --only-binary=llama-cpp-python to install all the required modules. If there is no pre-built llama-cpp-python wheel compatible with your hardware this will fail. In this case resort to the llama-cpp-python documentation for installing llama-cpp-python and install the rest of the packages from the requirements.
Download the data from https://huggingface.co/datasets/vidore/syntheticDocQA_energy_test_ocr_chunk/tree/main. Place the contents (test-00000-of-00002.parquet and test-00000-of-00002.parquet) into Capstone-RAG-project/data. Skip this step if you are using the zip as the data is already included.
This should take care of the basic setup, but if any modules are missing just install them with pip.
Special setup for GPU inference (optional)
To run the LLM inference locally, you need to have a GPU available. Beware that the following setup was only tested on Ubuntu 22.04.5 LTS and an nvidia GPU with compute capability 7.5. If you have different os or hardware you might have to deviate from these steps.
You need to have the cuda drivers and cuda toolkit installed and working (setup tested with version 12.1). If you have multiple versions make sure to have the correct one selected by running nvcc --version. To select another version run
export PATH=/usr/local/cuda-12.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH
Then to install the required packages with CUDA, run:
export GGML_CUDA=1
CMAKE_ARGS="-DGGML_CUDA=on"
pip install llama-cpp-python --upgrade --force-reinstall --no-cache-dir
pip install llama-cpp-haystack --upgrade --force-reinstall --no-cache-dir
Note that if you try this on Windows you will probably get an error. In this case I recommend trying a to use a pre-built wheel for your cuda version (something like pip install -r requirements.txt --force-reinstall --no-cache-dir --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/<cuda-version> --only-binary=llama-cpp-python), but I haven’t tried this so no guarantees.
Downloading models
If you would like to run inference, the model weights need to be downloaded from huggingface (the models are several GB each, you can choose to omit any of them just make sure to exclude them from the parameter search). In our study the following models were used:
- https://huggingface.co/bartowski/Mistral-7B-Instruct-v0.3-GGUF/resolve/main/Mistral-7B-Instruct-v0.3-Q4_K_M.gguf (included in zip)
- https://huggingface.co/bartowski/Llama-3.2-3B-Instruct-GGUF/resolve/main/Llama-3.2-3B-Instruct-Q6_K.gguf
- https://huggingface.co/bartowski/Llama-3.2-3B-Instruct-GGUF/resolve/main/Llama-3.2-3B-Instruct-Q3_K_L.gguf
- https://huggingface.co/S10244414/Mistral-7B-v0.3-Q5_K_M-GGUF/resolve/main/mistral-7b-v0.3-q5_k_m.gguf
The downloaded files should be placed in Capstone-RAG-project/model_weights
Running the Code
After completing the steps above, you can run the code. Run the querydata.py to extract the relevant part of the data from the raw data. Then run embed_document.py to embed the documents. You can run NO-RAG Chat.py to get the baseline performance from GPT-4o. The API key included in source should work, but if it does not, generate your own OpenAI API key. You can run eval_auto_pipeline_locallm.py to evaluate a combination of LLM and embedding model or do a parameter search across multiple ones. Note that this will take a long time especially if its running on the CPU. For the parameter search you have to specify the list of embedding models and LLMs in source. The embedding models are loaded automatically but the LLM’s .gguf file should be manually downloaded as described above. The parameters for the run need to be changed in source. Adjust the variables embedding_models, generator_models, temperature and repeat_penalty to reproduce specific runs. Set test to true if you want data on the test set. All the results are placed in the results folder.
Finally, run the Data Analysis Notebook to produce the plots from the data. The results are already generated, so you can run this straight away.
Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations 2/4
Description of program structure and design choiceslink copied
The following part gives an overview of our approach and process. It is not needed to reproduce the results, only to get a deeper understanding of the code.
File Structure
The project is structured as follows. In the root folder we have all the python files:
-
after_processing.py– A temporary solution to remove hallucinations from the LLM answers after they have been generated. Not used anymore. -
chat_pipeline.py– Used to generate RAG answers using the GPT4o mini. Handy to create example answers quickly, but does not include an evaluation. -
custom_component.py– Our custom haystack component to remove hallucinations in the main pipeline. -
Data Analysis Notebook.ipynb– Jupyter notebook to visualize results. Does not generate the results by itself, only reads csv-s in results folders. -
embed_document.py– Embeds the document database. Includes utility functions to load and save the database indata/. -
eval_auto_pipeline_locallm.py– Runs and evaluates the main pipeline using local LLM inference. Can be used for parameter optimization. Saves results into the results folder. -
eval_auto_pipeline.py– Somewhat deprecated but still functional version ofeval_auto_pipeline_locallm.py. Instead of local LLM inference, it uses Huggingface API calls. -
inspect_object.py– Inspect a pickled object for debugging. -
No_RAG_Chat.py– Used to generate and evaluate answers by calling GPT-4o without RAG. Its results used as a baseline. -
querydata.py– Initial preprocessing of the data. Takes the relevant fields (query, answer, text_content) from the provided.parquet˛files, merges tex chunks related to the same document together and saves the data in.jsonformat intodata/for further processing.
The folders are used as follows:
data/stores the initial raw data and the data used for intermediate steps, namelyquerys.json, an array of all questions in orderanswers.json, an array of all answers in orderdoc_lookup.json, a dictionary linking the unique document index to the originalDocMerged_<embedding model name>.json, file storing the document embeddings made by a certain model
model_weights/stores the .gguf files for local LLMsresults/stores the .csv files for the results in the following formatresults_<embedding model>_<LLM>_<temperature>_<repeat penalty>
results_<experiment name>folders are used to save out the results for a certain experiment where they would get overwrittentest_datais a json of all entries in the test set (only used to make sure that our split did not change)
There are some additional files for the environment configuration as well as this README.
Choice of Framework
As our main NLP framework we choose Haystack by Deepset AI. This is a high-level framework based on the transformers library. Haystack was the ideal choice for us, because it has very good abstractions for quickly creating and iterationg on modular pipelines, which was essential to reach our requirements.
For local inference we decided to use LlamaCpp, because we were VRAM constrained. LlamaCpp only allows loading part of the model into VRAM, while still efficiently utilizing the GPU. Moreover it is very easy to use with the quantized .gguf files available on huggingfacce for a large selection of models.
The rest of the packages we used are pretty standard, like pandas and numpy for basic data manipulation. These were chosen because they are easy to use and well-supported.
Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations 3/4
Main difficulties and solutionslink copied
During the coding we encountered a number of problems. When we wanted to merge text chunks by document, we ran into the error of duplicated documents (because now multiple questions had the exact same document associated with them). When embedding these documents we simply skipped the duplicates, however by doing this we lost the information about which question is paired to which document. This was later resolved by creating a dictionary in querydata.py storing these relationships.
We decided to limit our runs to local inference to force ourselves to use less resources, thus making our solution more sustainable. However, it was not easy to install llama-cpp-python with CUDA support as it would not use the GPU or on even break during installation. To fix the latter, we changed to using Linux, fixing the former led us to discover an error in haystack documentation about setting the right environment variables that is now patched thanks to our contribution.
When we got the pipeline working we discovered that the LLMs were hallucinating a lot, almost always following up with more questions and answers. As these always adhered to the same format we just instructed the LLM to stop generating after the string “Question:”. This did not only improve our results a lot, but also sped up the runtime slightly.
Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations 4/4
Limitations of the Designlink copied
The main performance limitations of the currant pipeline unfortunately is the data itself. The text-content chunks were extracted by OCR (Optical Character Recognition) and sometimes crucial information is missing or the extracted data is unintelligible. This could be fixed by using the PDF-s directly, like more advanced ColPali. However as seen in the paper, running (and training) a vision LLM uses much more resurces than our solution.
Another limitation stems from using the Haystack framework. Haystack’s Document object, thats used to store our documents and embeddings is non-serializable, therefore we can not parallelize our pipeline to process multiple queries at once. This might soon be fixed by the introduction of async pipelines.
Additionally, our design relies on a InMemoryDocumentStore, which is a simple Haystack document store with no extra dependencies. This was suitable for our project, as it requires no external setup and works for rapid prototyping. However, this limits the capability and reliability of our pipeline. The scalability of is hardware constrained, no multi-user support is capable and lacks more advanced feature like advanced indexing mechanisms. Therefore, a better back-end is advised for production.
Lastly, we are of course limited by LLM performance. The small quantized models we managed to run do not reach the quality of full-size SOTA LLMs like OpenAI’s o1 or DeepSeek’s R1. However, in return our pipeline can run on a personal computer, as opposed to million-dollar servers.
Write your feedback.
Write your feedback on "Leveraging Large Language Models for Policy Document Retrieval information in Energy Renovations"".
If you're providing a specific feedback to a part of the chapter, mention which part (text, image, or video) that you have specific feedback for."Thank your for your feedback.
Your feedback has been submitted successfully and is now awaiting review. We appreciate your input and will ensure it aligns with our guidelines before it’s published.