GAN MINST prediction
-
Intro
-
Data preperation
-
Generator
-
Discriminator
-
Training process
-
Conclusion
-
Useful Links
Information
| Primary software used | PUG |
| Course | GAN MINST prediction |
| Primary subject | AI & ML |
| Secondary subject | Machine Learning |
| Level | Advanced |
| Last updated | June 5, 2025 |
| Keywords |
Responsible
| Teacher | |
| Faculty |
GAN MINST prediction 0/6
GAN MINST prediction
GAN MINST prediction using the PUG plug-in in Grasshopper, covering data preparation, generator/discriminator roles, and training.
This tutorial introduces Generative Adversarial Networks (GANs) for MNIST digit prediction, specifically utilizing the PUG plug-in within Grasshopper. It guides users through data preparation, defining the roles of the generator and discriminator networks, and understanding the training process to synthesize realistic-looking handwritten digits.
GAN MINST prediction 1/6
Data preperationlink copied
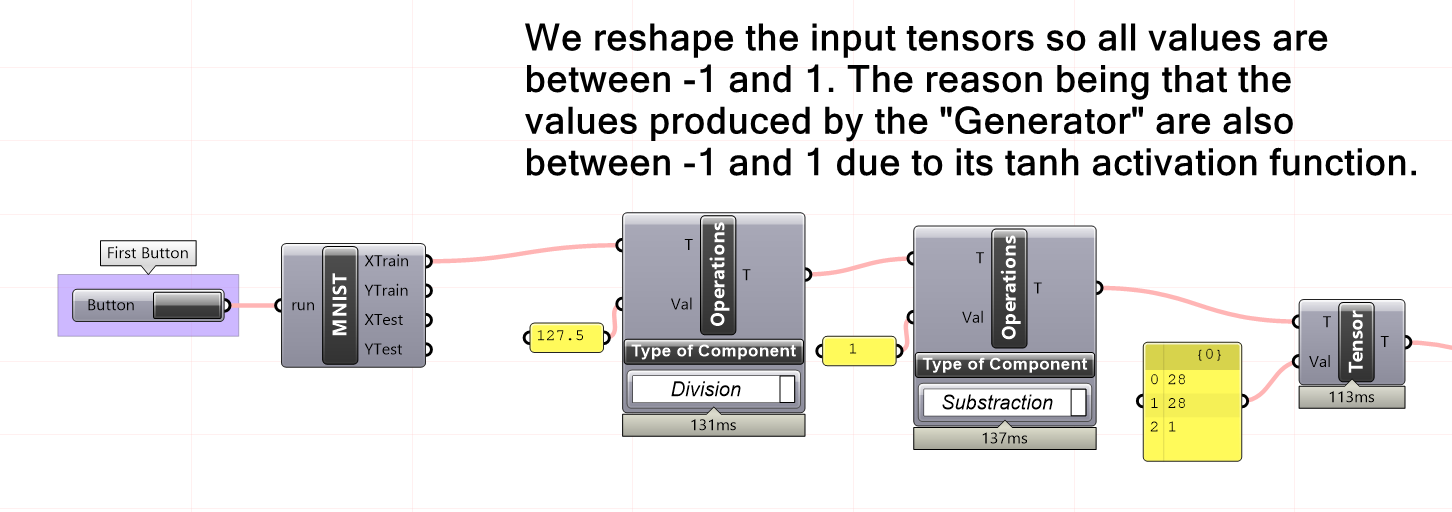
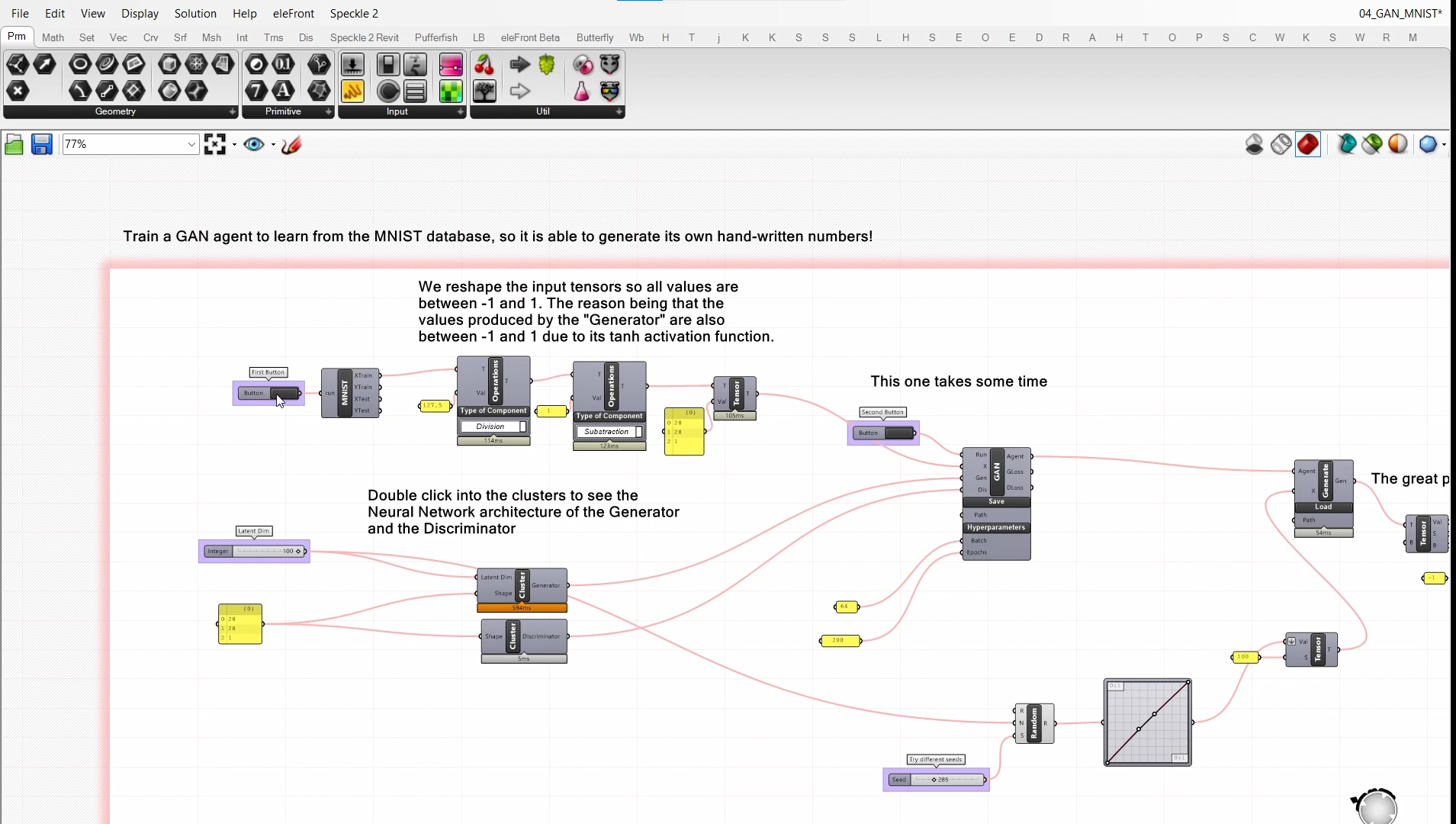
First, we reshape the MNIST data from -1 to 1. The reason for reshaping the MNIST data into the range of -1 to 1 is to scale the input data to a range suitable for training a GAN model. Scaling the data to this range helps the model converge faster and produces better results. Additionally, some GAN models are more sensitive to the scale of the input data, so normalizing the data is a good practice to ensure optimal performance.
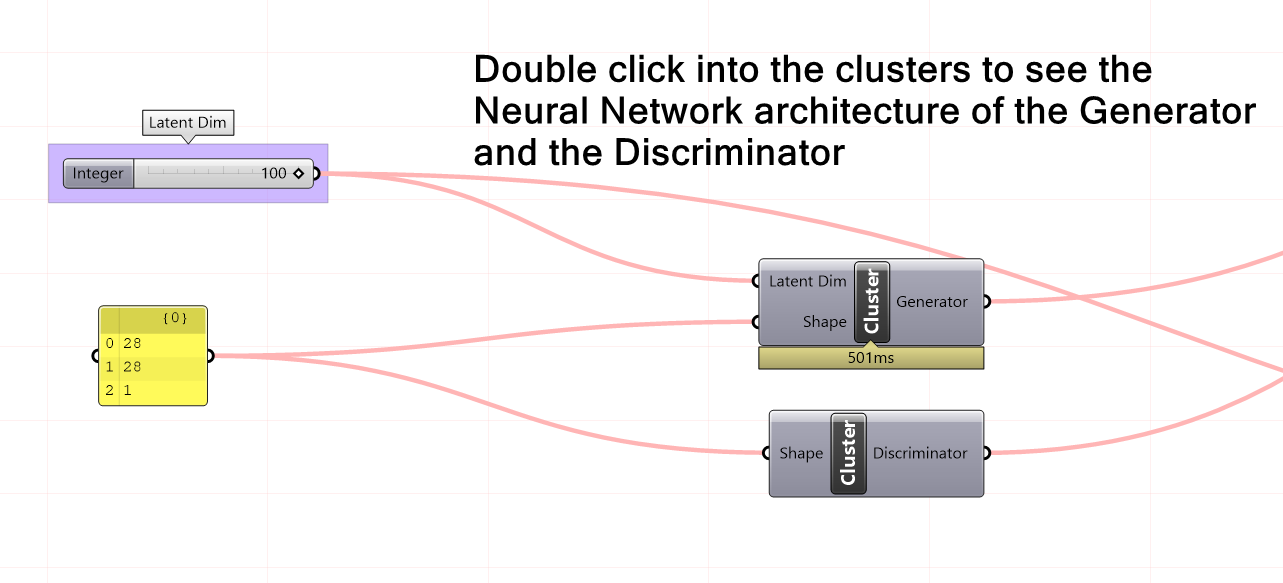
Let’s examine the generator and discriminator to understand the relationship between the shape and the input latent dimension.
GAN MINST prediction 2/6
Generatorlink copied
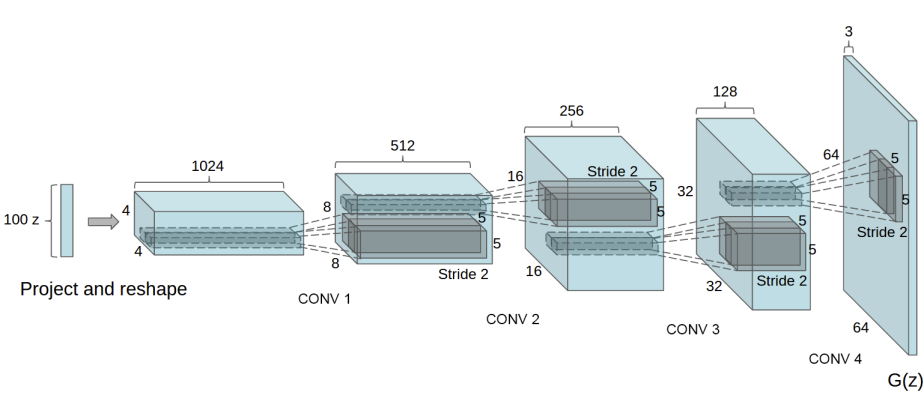
The generator in a GAN typically takes a random noise vector as input and produces a synthetic image as output. The input dimension of this noise vector is usually referred to as the latent dimension and determines the complexity of the generated images. A higher latent dimension allows for more diversity in the generated images, while a lower latent dimension restricts the range of possible outputs.
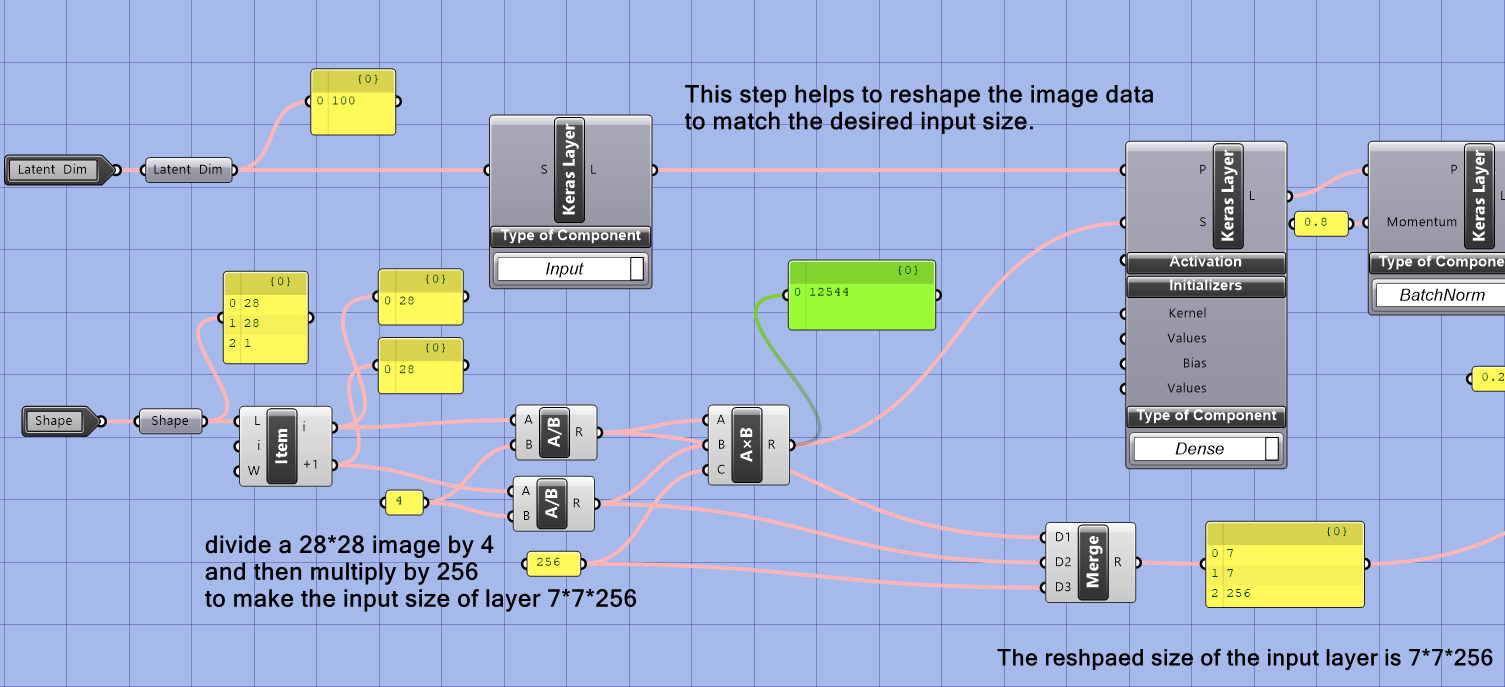
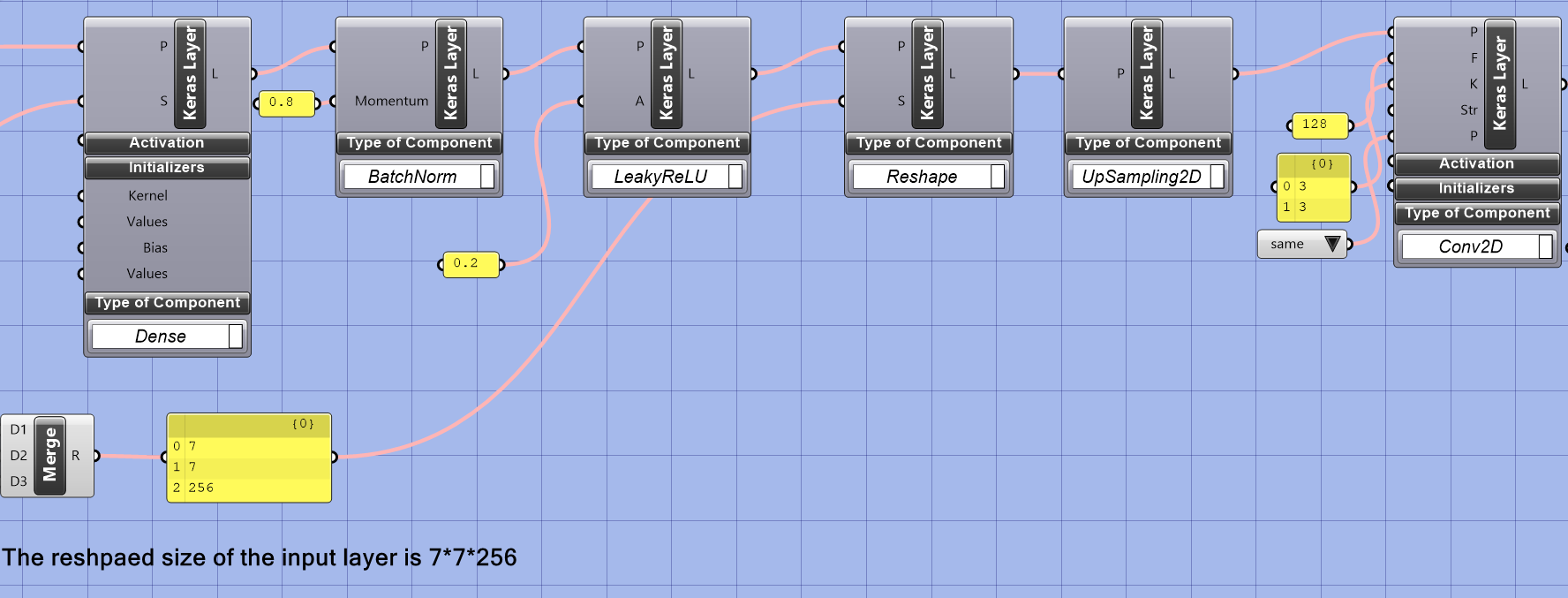
This model needs to divide a 28*28 image by 4 and then multiply by 256 to make the input size of layer 7*7*256 because the generator architecture in this model requires the size of the input layer to be 7*7*256. This step helps to reshape the image data to match the desired input size.
Note that: The choice of the number 7 for the size of the layer’s input in a GAN model is a design decision made by the model creators and is not a strict requirement. It can be any other number, but it’s essential to keep in mind the balance between a large enough input size for the model to learn meaningful representations and avoiding an excessively large input size that may lead to increased training time and overfitting.
The choice of 7 as the size of the image is often a design decision made by the network architect. This specific size was probably chosen to balance the computational cost of the network and its ability to generate high-quality images. After the image is down-sampled to 7×7, batch normalization, leaky ReLU activation, upsampling, 2D convolutional, and reshape operations are used to generate the final image in the generator. These operations help increase the image’s spatial resolution and add fine-grained details. These operations are commonly used in GAN architectures to improve image generation capabilities.
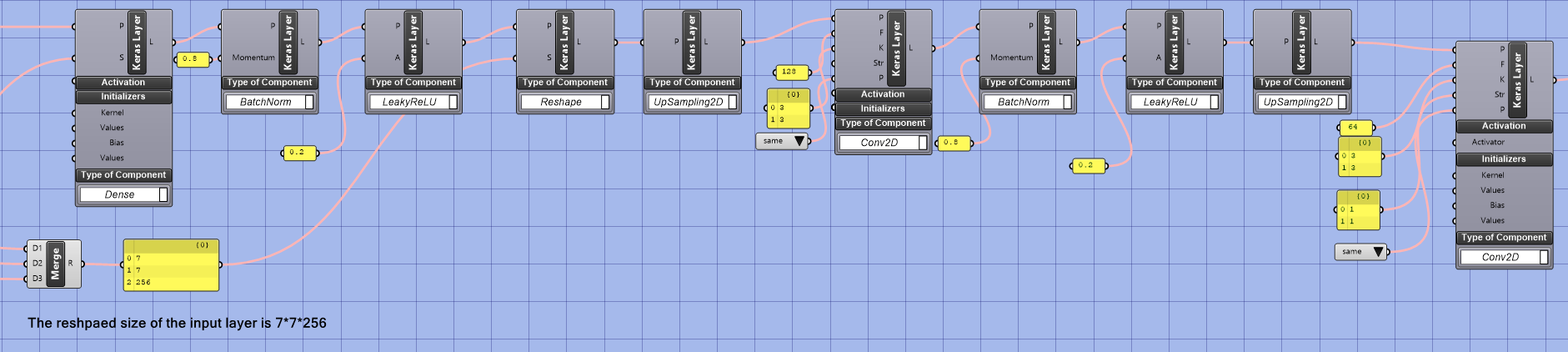
- Batch normalization: is a normalization technique used to speed up the training of deep neural networks. It helps stabilize the activation values distribution during the forward pass.
- Leaky ReLU activation function: is a variation of the ReLU activation function that allows a slight, non-zero gradient when the input is negative. This helps to prevent the vanishing gradient problem in deep neural networks.
- Upsampling: It is an operation in computer vision and image processing that increases an image’s size by inserting zeros between the existing pixels. In deep learning, it is often used in the generator part of a GAN.
- 2D convolutional: is a convolution operation in which the convolutional filters are applied to the input in a 2-dimensional manner. It is widely used in image processing and computer vision tasks.
- Reshape: is an operation in deep learning that changes the shape of a tensor, for example, from a 2D matrix to a 1D vector.
The 2D convolutional layer in a neural network uses a filter (also known as a kernel) to extract features from the input image. The padding argument determines the number of pixels added to the input tensor along the height and width dimensions. The “same” padding option adds the same number of pixels to both the top and bottom and the left and right of the tensor so that the height and width of the output tensor remain the same as the input tensor. This helps preserve the input image’s spatial resolution and prevents shrinking and losing information in the spatial dimensions during the convolution operation. The number of filters determines the number of feature maps the 2D convolutional layer will learn. Sixty-four filters mean the layer will learn 64 different feature maps. The size of the kernel (3×3) determines the size of the window that slides over the input to extract features, and the stride of 1 means that the kernel will move one pixel at a time. This setting is used to preserve the spatial resolution of the input, as the “same” padding replicates the border pixels to maintain the spatial dimensions of the output tensor.
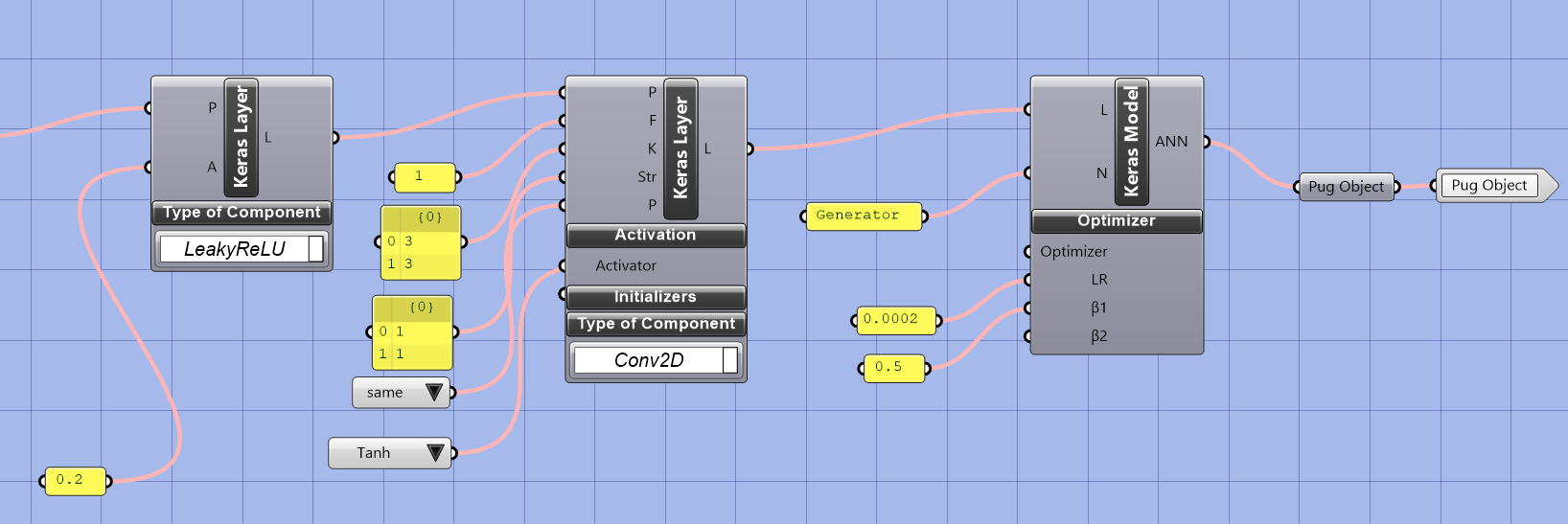
The whole definition of the network structure is connected to a Keras model. The learning rate is set to 0.0002, which determines how fast the model learns from the data. The beta1 parameter of the Adam optimizer is set to 0.5, which influences the gradient descent algorithm used to optimize the model. The output of this process is a Pug object, which can be used to perform predictions and evaluate the network’s performance. The choice of learning rate and beta1 parameters can impact the stability and speed of the training process, so it is crucial to choose them carefully based on the problem at hand and the characteristics of the data.
GAN MINST prediction 3/6
Discriminatorlink copied
A discriminator in a GAN is a neural network that separates real data from generated data. It acts as a “critic” to distinguish real from fake data, with the generator’s goal being to produce fake data that is indistinguishable from real data.
The input dimension of the discriminator depends on the data it is working with, such as a 2D tensor with shape (height, width, channels) for images. The output is a scalar value representing the probability that the input is real. The generator and discriminator compete with each other, with the generator improving based on the feedback from the discriminator.
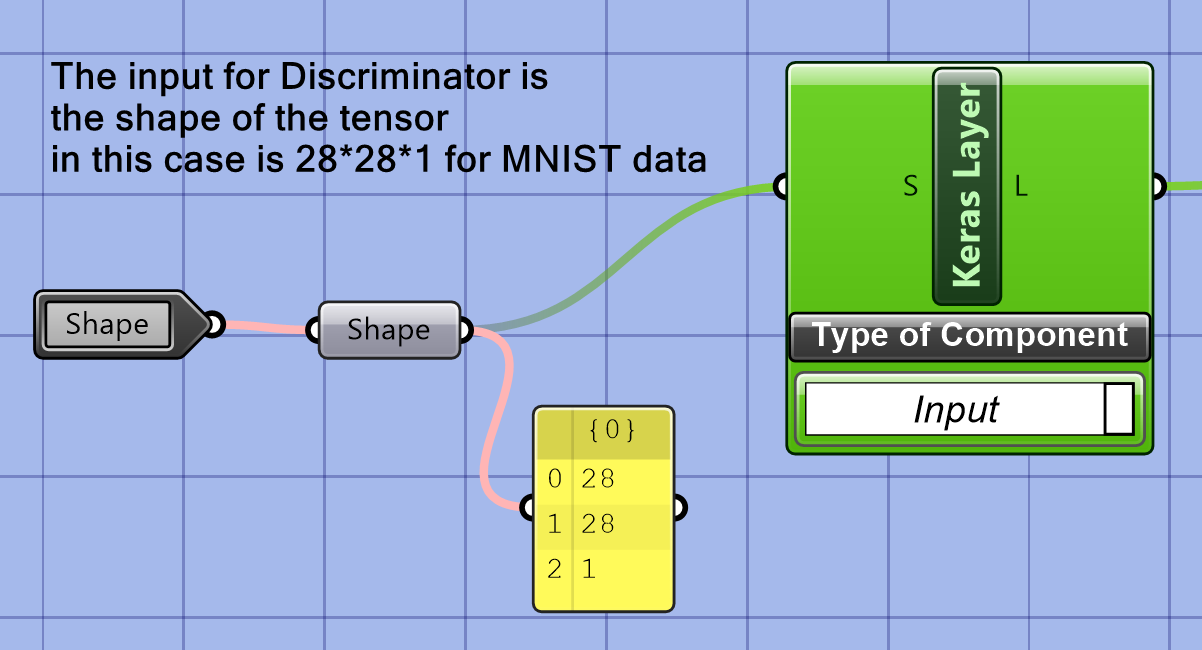
The input to the Discriminator in a GAN network is a tensor representing an image; in this case, for MNIST data, it is a 2D tensor of shape 28 x 28 x 1, representing the height, width, and number of color channels of the image. The height and width specify the image’s dimensions, and the number of color channels represents the depth of the image, typically either 1 for grayscale or 3 for RGB.
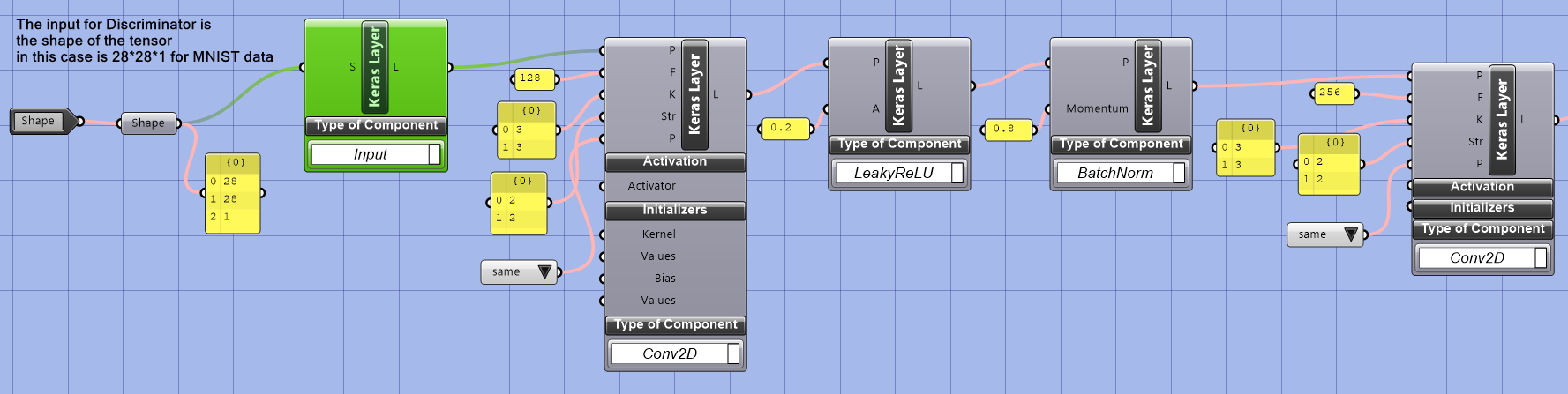
After the input layer, a series of convolutional layers (conv2d), leaky ReLU activation functions, and batch normalization layers are used to build the discriminator network. The purpose of these layers is to extract meaningful features from the input image and normalize the inputs, stabilize the training process, and prevent overfitting.
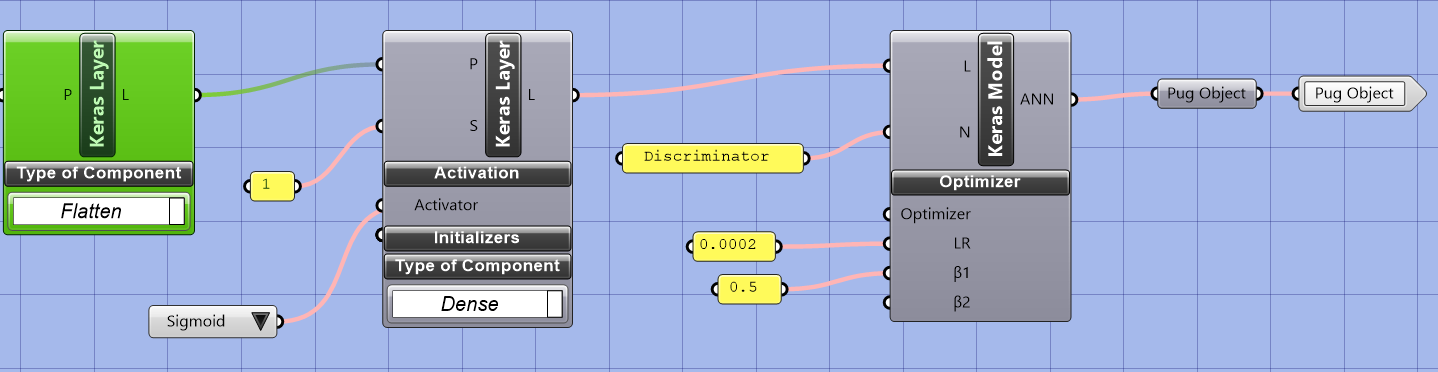
After the series of Conv2D, LeakyReLU, and BatchNorm layers in a Discriminator, there will typically be a dense layer and a flatten layer. The flatten layer reshapes the previous layer’s output into a 1D tensor, as dense layers require a 1D input. The combination of the dense and flatten layers form the final decision-making stage of the output of a single scalar value representing the probability that the input sample is real.
GAN MINST prediction 4/6
Training processlink copied
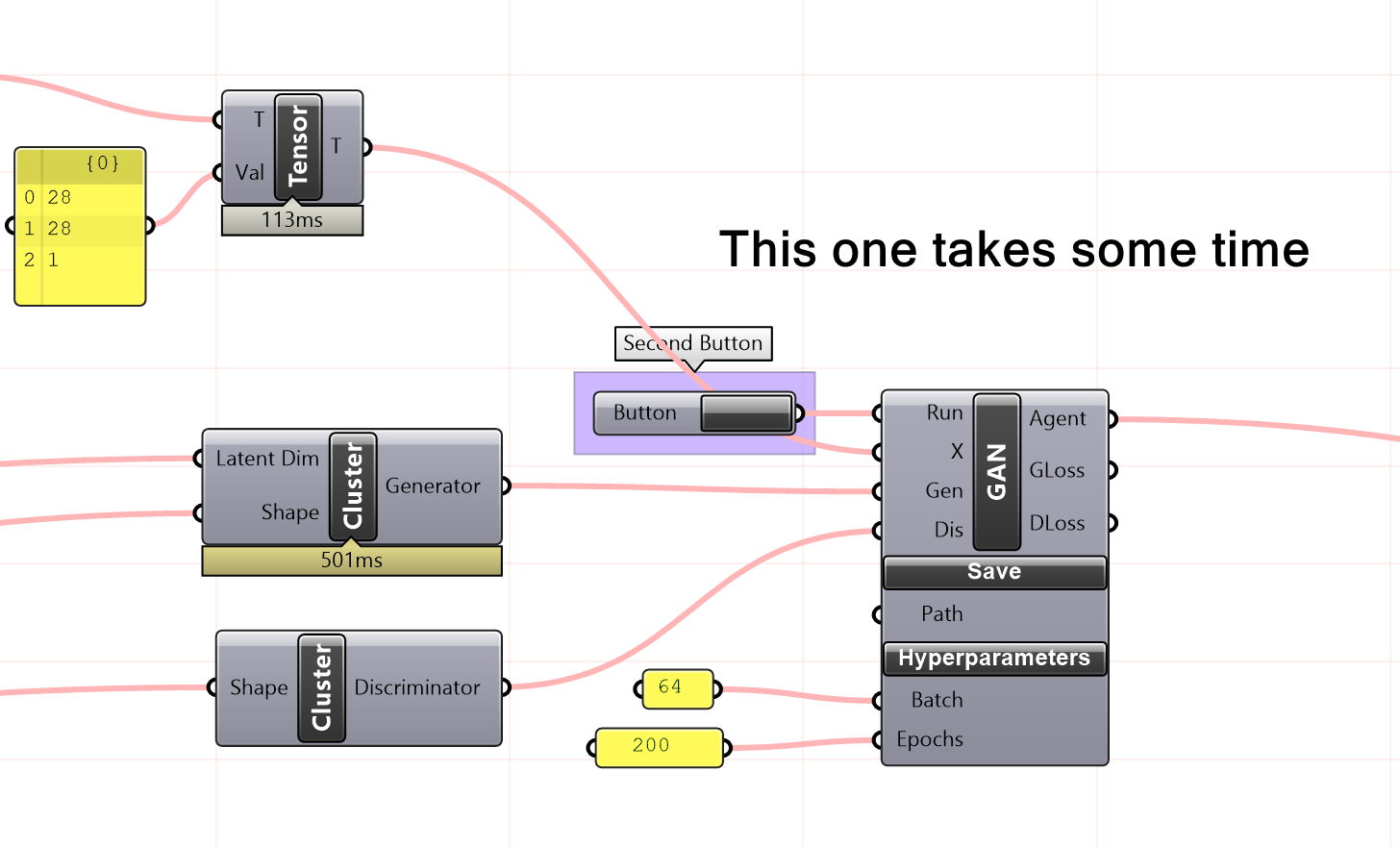
After importing the MNIST dataset into the GAN model, the next step is to initiate the training process by pressing the second button. This will enable the model to learn from the data and improve its performance.
Here is a video to show how to train the model.
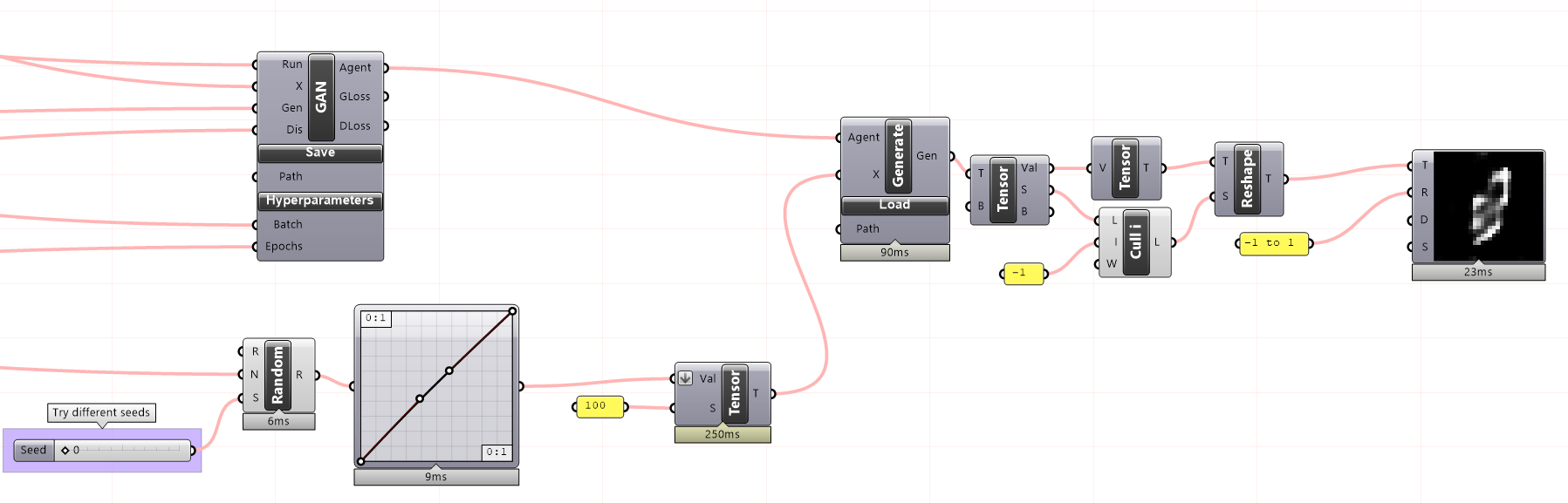
The generator in a GAN takes a randomly generated tensor as input, which acts as a representation of the latent space. The generator’s goal is to map this input tensor to synthetic data similar to the real data. The input tensor can be adjusted to control the characteristics of the generated synthetic data, in this case, the MNIST dataset. The generator then uses this input to produce a synthetic sample similar to the real data.
GAN MINST prediction 5/6
Conclusionlink copied
You now learned how to use the plug-in PUG for a GAN problem in Grasshopper. Here you can find an overview of the script.
Final exercise file
Here you find the final GH script of the tutorial.
GAN MINST prediction 6/6
Useful Linkslink copied
External resources
Wiki pages:
- Batch normalization
- Leaky ReLU activation function
- Upsampling
Interesting articles:
- 2D convolutional: Intuitively Understanding Convolutions for Deep Learning
- Reshape
Write your feedback.
Write your feedback on "GAN MINST prediction"".
If you're providing a specific feedback to a part of the chapter, mention which part (text, image, or video) that you have specific feedback for."Thank your for your feedback.
Your feedback has been submitted successfully and is now awaiting review. We appreciate your input and will ensure it aligns with our guidelines before it’s published.